
![[Imágenes: annetdebar/Adobe Stock; Avector/Adobe Stock]](https://fc-bucket-100.s3.amazonaws.com/wp-content/uploads/2026/03/30120319/p-1-91517596-ai-is-teaching-us-to-speak-like-bots.webp)
![[Imagen: Adobe]](https://fc-bucket-100.s3.amazonaws.com/wp-content/uploads/2026/03/30113841/p-1-91518262-illustrator-update.webp)
![[Foto: Jim Watson – Pool/Getty Images]](https://fc-bucket-100.s3.amazonaws.com/wp-content/uploads/2026/03/31114253/mujer-trabajadores-ICE-Fast-Company-Mexico-Cortesia.webp)
 [Ilustración: FC]
[Ilustración: FC]




Google ha dedicado la última década y media a redefinir su cultura de ingeniería como una empresa centrada en el diseño. Sin embargo, una escena reciente ocurrida en los tribunales refutó con tristeza esta narrativa, señalando a Google como totalmente incompetente en el diseño o manipulador en su práctica.
La compañía se ha enfrentado a un jurado federal esta semana en California en relación con una demanda colectiva que alega que, entre 2016 y 2024, Google guardó y utilizó información “seudónima” sobre sus usuarios sin su consentimiento. A pesar de que los clientes optaron por no participar en la recopilación de datos en los servicios de Google, la demanda alega que Google siguió accediendo a sus datos recopilados a través de aplicaciones de terceros. ¿Cómo? Google accedió a los datos rastreados por su propio software de análisis integrado en estas aplicaciones. —Google no había respondido a una solicitud de comentarios al momento de la publicación—.
Así explicado, parece casi obvio que Google podría tener acceso a los datos. Pero, claro, la mayoría de los usuarios desconocen qué software de análisis utilizan sus aplicaciones y, además, los demandantes argumentan que 98 millones de personas optaron por que Google no recopilara sus datos de terceros. Creían estar protegidos, incluso si existían otros términos y condiciones ocultos ofrecidos por cada aplicación.
Defendiendo el mal comportamiento
Como parte de su defensa, Google presentó a una experta, la profesora Donna Hoffman de la Universidad George Washington, para argumentar su caso. Según Law360, Google utilizó una técnica de “divulgación progresiva” para que la información más importante se comunicara primero a los usuarios. Hoffman también afirmó que empleó un “buen diseño de interfaz de usuario” para evitar la “sobrecarga cognitiva”.
La divulgación progresiva no es una práctica de experiencia de usuario intrínsecamente engañosa; si se realiza correctamente, esta técnica puede revelar más sobre las capacidades de un servicio o aplicación en relación con la capacidad de atención del usuario. Se aprende más sobre ella, poco a poco, con el tiempo. Los videojuegos se diseñan en torno a este mismo principio. Se aprende cómo salta Mario antes de aprender cómo vuela. Hoffman afirmó que era una técnica que Google utilizaba para satisfacer a sus muy diversos estilos de usuarios, que interactúan con el lenguaje legal de distintas maneras y a quienes Google denomina “skippers, skimmers y readers” —saltadores, lectores superficiales y lectores completos—.
Pero que Google aproveche la divulgación progresiva en este caso es falso, y ofrezco este análisis como experto en diseño —que no recibe compensación económica como testigo experto—. Nada en términos de diseño impide que Google ofrezca un único interruptor en su página de inicio para que el usuario pueda optar por no participar en ningún tipo de seguimiento potencial de Google para siempre.
Eso no sobrecargaría la cognición de nadie, especialmente comparado con el extraño laberinto de configuraciones y páginas explicativas que Google utiliza para indexar asuntos de privacidad. Los demandantes incluso presentaron pruebas de que los empleados de Google dudaban de haber proporcionado la información de privacidad adecuada a los usuarios.
Otros gigantes tecnológicos hacen lo mismo
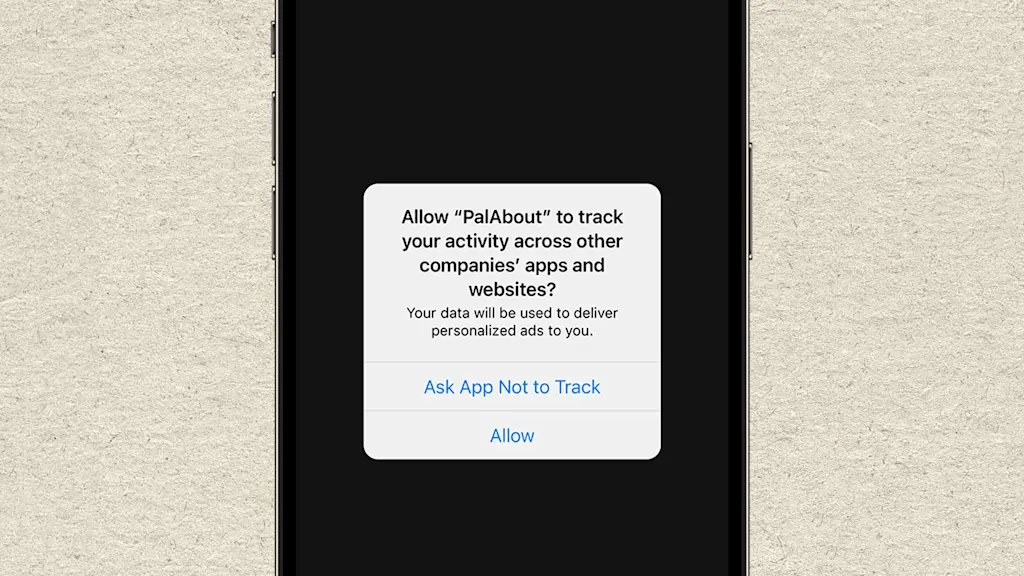
Google no es el único actor negativo en este ámbito. Apple creó la distopía de privacidad en la que vivimos tanto como cualquier otro competidor. A día de hoy, ofrece una pésima experiencia de usuario a los usuarios de iPhone, quienes deben “permitir” o “pedir a la app que no los rastree” en una ventana emergente, en lugar de simplemente denegar la solicitud en nombre de sus clientes. Siempre me preocupa que se me resbale el pulgar y elija la opción equivocada, cuando la opción anticonsumidor ni siquiera debería presentárseme, y mucho menos de una empresa que afirma priorizar la privacidad.
Si Google pierde este caso, la indemnización a los consumidores podría ser considerable. Los demandantes estiman el valor de los datos en 3 dólares al mes. Y con 173 millones de clientes afectados, la indemnización ascendería a 29,000 millones de dólares en daños y perjuicios.
A medida que las empresas se inmiscuyen aún más en nuestras vidas, ofreciendo al software de Inteligencia Artificial acceso directo a nuestros datos personales, la información sobre privacidad se volverá cada vez más turbia y compleja. Incluso si los demandantes ganan este juicio, la lucha por nuestra privacidad parece una batalla perdida.
![[Fotos:
wang binghua/Unsplash;
Shekai/Unsplash; vfhnb12/Getty Images]](https://fc-bucket-100.s3.amazonaws.com/wp-content/uploads/2026/03/30151147/p-1-91513692-apple-most-important-contribution-50-years-policy-privacy-encryption-cloud-craig-federighi-ai.webp)
