![[Imagen: Tiendanube;
rawpixel.com/Magnific]](https://fc-bucket-100.s3.amazonaws.com/wp-content/uploads/2026/07/30101941/Lumi-Tiendanube-IA-Fast-Company-Mexico-Magnific.jpg)
![[Foto de origen: Adobe Stock]](https://fc-bucket-100.s3.amazonaws.com/wp-content/uploads/2026/07/29153007/p-91573455-your-calendar-is-your-culture.webp)
![[Foto: Chris Ratcliffe/Bloomberg/Getty Images]](https://fc-bucket-100.s3.amazonaws.com/wp-content/uploads/2026/07/29081657/3-3.jpg)
![[Imagen: Pixabay]](https://fc-bucket-100.s3.amazonaws.com/wp-content/uploads/2026/07/29094957/trabajadores-50-anos-talento-senior.jpg)
 [Imágenes: sripfoto/Adobe Stock; backup16/Adobe Stock]
[Imágenes: sripfoto/Adobe Stock; backup16/Adobe Stock]




Desde 2017, el proyecto Common Voice de Mozilla ha recopilado más de 30,000 horas de grabaciones de personas de todo el mundo hablando sus idiomas.
El objetivo del proyecto es proporcionar un conjunto de datos gratuito y de acceso público que cualquiera pueda utilizar para entrenar software de inteligencia artificial de reconocimiento de voz y otros proyectos, al tiempo que se garantiza que todo el material se proporciona con el consentimiento informado de las personas que se graban.
Common Voice ahora incluye material grabado y transcripciones correspondientes en aproximadamente 180 idiomas. Todos están disponibles bajo la licencia Creative Commons CC0 de dominio público, con voluntarios de todo el mundo trabajando para agregar sus propios idiomas.
“No agregamos idiomas a la plataforma sin comunidades”, dice EM Lewis-Jong, director de productos de Mozilla. “Parece algo pequeño, pero creo que en la era actual de la inteligencia artificial, en realidad es extrañamente radical centrarse en el consentimiento”.
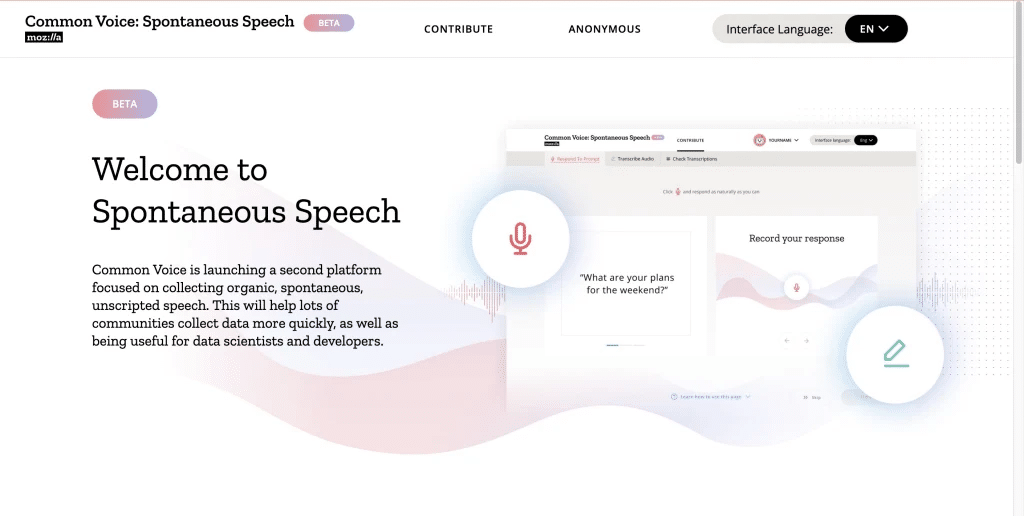
¿Cómo se están utilizando estos datos?
Y aunque Mozilla no revela—o en algunos casos ni siquiera necesariamente sabe—exactamente quién está usando los datos, Lewis-Jong dice que han sido utilizados por grandes empresas tecnológicas, pequeñas operaciones independientes y muchos proyectos intermedios. El conjunto de datos se ha descargado de Mozilla millones de veces y también está disponible a través de la plataforma de desarrollo de IA Hugging Face, que aloja modelos de reconocimiento de voz entrenados con los datos de Common Voice.
En algunos casos, el conjunto de datos ha sido utilizado por proyectos más pequeños centrados en tareas específicas, como brindar asesoramiento legal multilingüe, brindar información sobre gobernanza o crear chatbots con información agrícola local que funcionen por voz.
“Creo que es justo decir que, desde las organizaciones tecnológicas más grandes y famosas hasta proyectos de la sociedad civil realmente pequeños y desarrolladores individuales, realmente vemos todo el espectro”, dice Lewis-Jong.
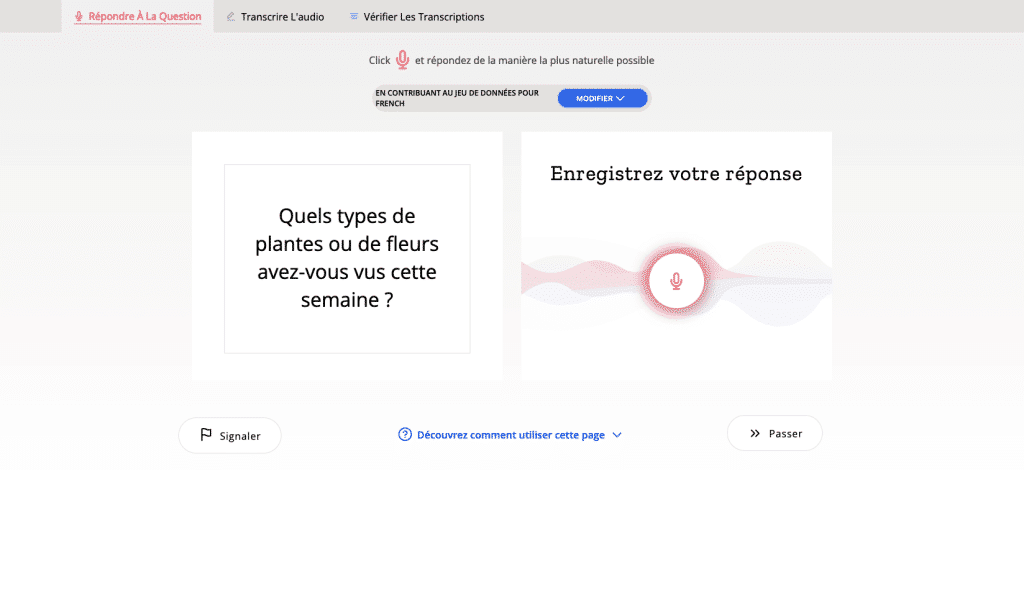
El proyecto es cada vez más grande y ambicioso
Common Voice sigue creciendo a medida que se graba material nuevo en idiomas existentes y nuevos voluntarios se acercan a Mozilla para localizar la contribución para sus propios idiomas. Esto permite a los contribuyentes grabar, validar y transcribir material que se agrega a futuras versiones.
Al principio, Common Voice principalmente incitaba a las personas a leer en voz alta textos de dominio público. Pero a medida que se expandió de idiomas con una gran cantidad de textos de dominio público para que los voluntarios leyeran a otros con menos material de ese tipo, el proyecto agregó indicaciones más generales, invitando a personas de diferentes comunidades a responder preguntas generales. Sus respuestas, lo que Mozilla llama “discurso espontáneo” sobre el tema, luego son transcritas por voluntarios.
Los voluntarios a menudo han incluido personas interesadas en proporcionar conjuntos de datos abiertos, personas que desean ver más herramientas de IA disponibles en sus idiomas y personas interesadas en la preservación del idioma. Por ejemplo, los defensores del gobierno de la lengua galesa han instado a los hablantes a contribuir al proyecto, y los hablantes de otras lenguas de todo el mundo han contribuido por orgullo lingüístico y por el deseo de que su lengua se incluya en los asistentes de voz y las herramientas tecnológicas del futuro.
Voces hacia el futuro
Irvin Chen, organizador de la comunidad lingüística del proyecto en Taiwán, dice que antes de Common Voice, no había ningún conjunto de datos disponible de las lenguas habladas en Taiwán aparte del mandarín. En 2022 se lanzó un proyecto en lengua taiwanesa en Common Voice. Ahora, Chen y otros están trabajando con hablantes de lenguas indígenas de todo Taiwán para que también se las agregue.
“Una vez que empecemos a grabar y tengamos el resultado, será un recurso que beneficiará para siempre a todas las investigaciones y tecnologías futuras”, dice Chen, señalando que tener sistemas precisos de voz a texto en taiwanés podría beneficiarlo a él y a otras personas que pueden hablar el idioma pero no pueden escribirlo con fluidez.
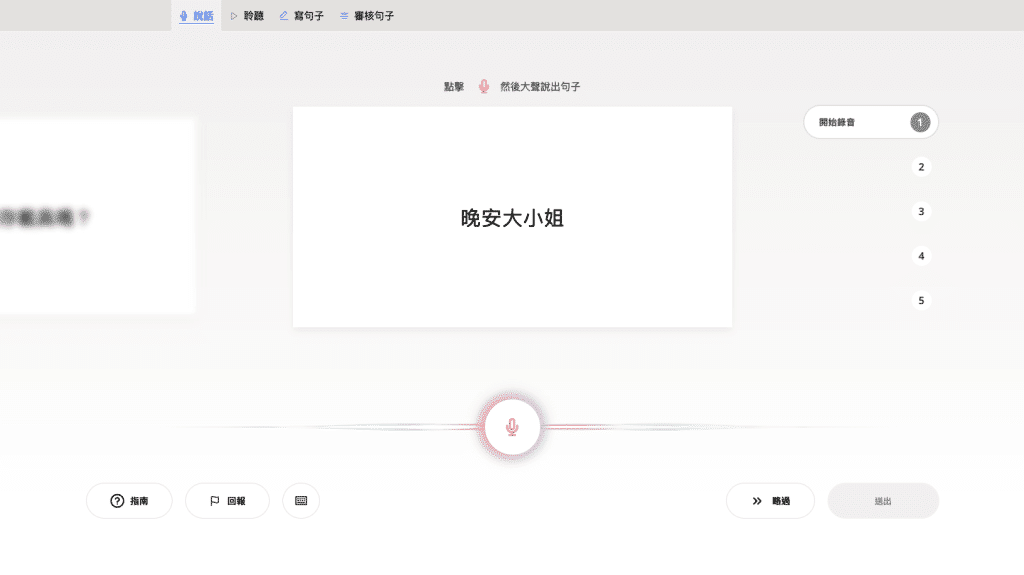
[Imagen: Mozilla]
“Para eso, es muy importante que tengamos una base de datos para que los investigadores creen la información de voz a texto”, dice.
Desafíos tecnológicos
A medida que Common Voice se expande, explica Lewis-Jong, el proyecto tiene que evolucionar técnicamente para dar soporte a idiomas que no coinciden con todas sus suposiciones iniciales sobre los recursos disponibles.
“Lo que vemos ahora es que cada vez se suman más idiomas con menos recursos, lo que ha sido un desafío tecnológico realmente interesante, porque gran parte de la forma en que se construyen las plataformas y la tecnología está realmente optimizada para idiomas con muchos recursos”, dice. “Por lo tanto, ahora tenemos que adaptarnos sobre la marcha para intentar asegurarnos de que podemos dar cabida a personas que tal vez hablen un idioma que no tenga ningún sistema de escritura estandarizado, o dar soporte a personas cuyos idiomas no existen de forma aislada, sino que tienen muchos otros idiomas mezclados”.
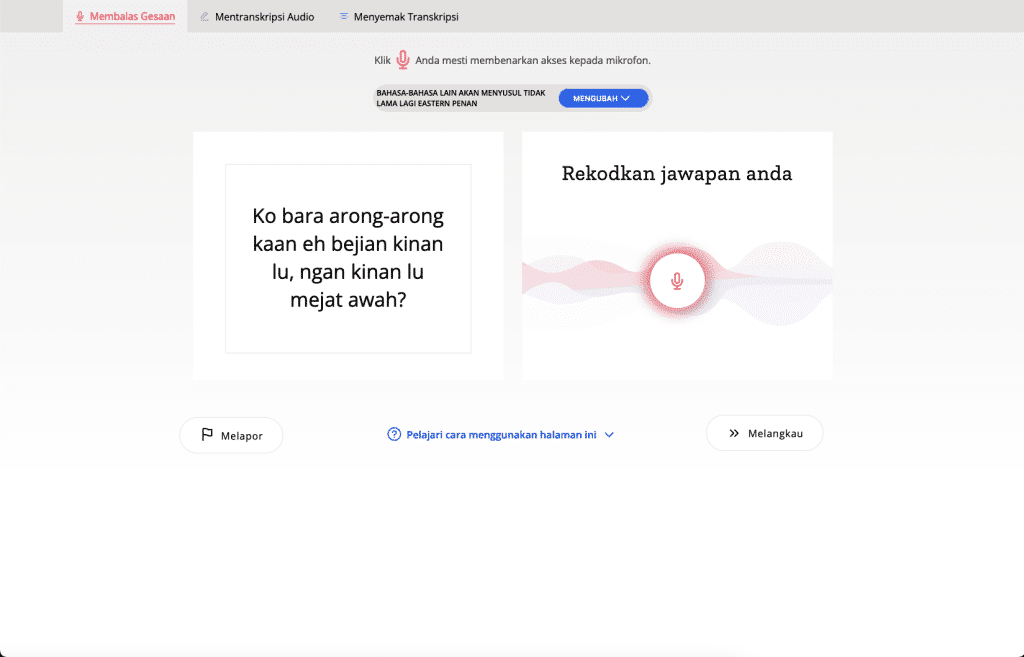
[Imagen: Mozilla]
Mozilla también está trabajando en un programa piloto con algunas comunidades de lenguas africanas para permitir que los conjuntos de datos de idiomas se publiquen bajo licencias más restrictivas. Es una posible respuesta a los contribuyentes que están preocupados por poner los datos a disposición de forma totalmente gratuita, incluso para las grandes y ricas empresas tecnológicas o para proyectos a los que podrían oponerse.
Y aunque todavía se están definiendo los detalles, Lewis-Jong dice que las licencias podrían estar diseñadas para permitir que ciertos tipos de organizaciones utilicen los datos de forma gratuita, mientras que se esperaría que otras hicieran una contribución a la comunidad o impusieran ciertas reglas para la atribución de los datos.
“Todo esto es un territorio nuevo para nosotros, porque históricamente solo hemos permitido que la gente cree conjuntos de datos y los publique bajo la licencia más abierta posible”, dice. “Por lo tanto, será un experimento realmente interesante para las comunidades, para los consumidores de datos y para nosotros”.
![[Imagen: Google; Umut Hasanoglu/Unsplash]](https://fc-bucket-100.s3.amazonaws.com/wp-content/uploads/2026/07/27153827/google-gmail-anuncios-inteligencia-artificial.jpg)
![[Captura de pantalla: OpenGridWorks]](https://fc-bucket-100.s3.amazonaws.com/wp-content/uploads/2026/07/28134939/p-1-91580467-mapping-the-worlds-power-plants.webp)